Продолжаю решать задачи на LeetCode. Сегодня мой мозг рубится с задачей Longest Substring Without Repeating Characters. На моем сайте в рубрике Решаем задачи вы можете посмотреть обзоры решения других задач с данной платформы.
Условия задачи
Дана строка. Необходимо найти длину самой длинной подстроки без повторяющихся символов. Строка может состоять из букв английского алфавита, цифр, символов и пробелов. Строка может быть и пустой (надо это учесть в ходе решения).
Что такое подстрока и подпоследовательность
Что-то задача не поддается решению. Значит, надо буквально разобрать условие по словам, чтобы глубже понять и осознать, что от меня требуется.
Итак, уже в самом заголовке задачи есть термин «подстрока», которому необходимо дать определение.
Подстрока – непрерывная последовательность подряд идущих символов в строке. В свою очередь, сама строка – это также последовательность символов.
Применительно к условиям задачи: “abcabcbb” – это строка, а “abc” – это подстрока, которую мне и необходимо найти.
Но в числе примеров к данной задаче, есть один пример, который пока ломает все мои подходы к решению.
Дана строка: “pwwkew”. Самой длинной не непрерывной подстрокой для данной строки будет подстрока “wke”. В примере авторы задачи обращают наше внимание на то, что ответ должен быть подстрокой, а “pwke” — это подпоследовательность, а не подстрока.
Подпоследовательность — это последовательность, которую можно получить из другой последовательности путем удаления некоторых элементов без изменения порядка остальных элементов.
Демонстрация подпоследовательности:

Первый подход (неверный)
Вначале определю список substring, в который буду добавлять все неповторяющиеся символы в строке s. Циклом for прохожусь по строке s. На каждой итерации цикла делаю проверку, если символа в списке substring нет, то я его в него добавляю. На первой итерации первый символ строки сразу попадет в список substring, так как список еще пуст.
Прогоняю через функцию три варианта входных данных (“abcabcbb”, “bbbbb”, “pwwkew”) и получаю следующие результаты: [‘a’, ‘b’, ‘c’], [‘b’] и [‘p’, ‘w’, ‘k’, ‘e’], соответственно.
Первые два результата полностью удовлетворяют условиям задачи, а вот с третьим результатом есть проблемка, это как раз подпоследовательность, а не подстрока. Ну хорошо, согласен, это все подпоследовательности, только в первых двух случаях подпоследовательность совпадает с подстрокой, а вот в третьем случае — нет.
Отрицательный результат – это тоже результат, так что продолжаю думать. На третьем примере входных данных видно, что символ “p” не должен войти в искомую подстроку, так как между “p” и “k” есть две повторяющиеся буквы “w”, что должно прервать подстроку.
Подробнее про третий случай
То есть, на первой итерации цикла я беру первый символ в строке “pwwkew” и добавляю его в список substring. На второй итерации я беру символ “w”, который является вторым по счету, и сравниваю его со списком substring. Совпадений не выявлено, добавляю его в подстроку.
А вот на третьей итерации, получив для сравнения третий символ “w” строки s я увижу совпадение, так как символ “w” уже есть в списке substring (был добавлен на второй итерации работы цикла for).
И вот в этот самый момент нужно сделать паузу и подумать, а что делать дальше. По сути, у меня получилась одна подстрока, которая состоит из “pw”, и вторая подстрока, которая состоит из “wke”. По хорошему, мне бы их как-то распознать и сохранить, чтобы затем выбрать из них самую длинную.
Второй подход (верный, но медленный)
Первый подход так и не увенчался успехом, поэтому я отложил решение этой задачи и переключился на написание тестов для своих Telegram ботов. Впрочем, вторая попытка оказалась удачнее.
Предлагаю сразу обработать два случая:
- когда метод на вход получает пустую строку (в этом случае возвращаем 0);
- когда метод получает строку, которая состоит из одинаковых символов (в такой ситуации возвращаем 1, так как длина уникальной подстроки будет равна единице).
if not s:
return 0
if max(s) == min(s):
return 1
Отлично, можно идти дальше. Инициализирую два пустых списка:
- substring – в этот список буду добавлять неповторяющиеся символы.
- substring_length – в этом списке буду хранить длину неповторяющихся подстрок, чтобы в дальнейшем выбрать максимальное значение, то есть самую длинную подстроку.
На следующем этапе перебираю все символы в строке. Перебор буду осуществлять с помощью двух циклов for.
Внешним циклом for прохожусь по индексам символов в строке, а вложенным циклом for уже непосредственно перебираю символы. Индексы нужны для нарезания отрезков входящей строки, так как искомая подстрока может находиться внутри строки.
for index_symbol in range(len(s)):
for symbol in s[index_symbol:]:
pass
Далее делаю проверку, нет ли символа в списке substring. Если символ ранее не был добавлен в список substring, то методом append я его туда добавляю и перехожу к следующей итерации вложенного цикла for, на которой проверяю следующий символ итерируемого отрезка строки s.
Как только встречается символ, который уже есть в списке substring, в дело включается блок else.
В список substring_length добавляю длину списка неповторяющихся последовательно расположенных символов в списке substring, а затем очищаю список substring и прерываю вложенный цикл.
if symbol not in substring:
substring.append(symbol)
else:
substring_length.append(len(substring))
substring.clear()
break
Вот и все, осталось только дождаться полного выполнения циклов, а затем вернуть максимальное значение из списка substring_length. Это и будет искомая длина максимальной подстроки без повторения.
return max(substring_length)
Полный код решения задачи
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
if not s:
return 0
if max(s) == min(s):
return 1
substring = []
substring_length = []
for index_symbol in range(len(s)):
for symbol in s[index_symbol:]:
if symbol not in substring:
substring.append(symbol)
else:
substring_length.append(len(substring))
substring.clear()
break
return max(substring_length)
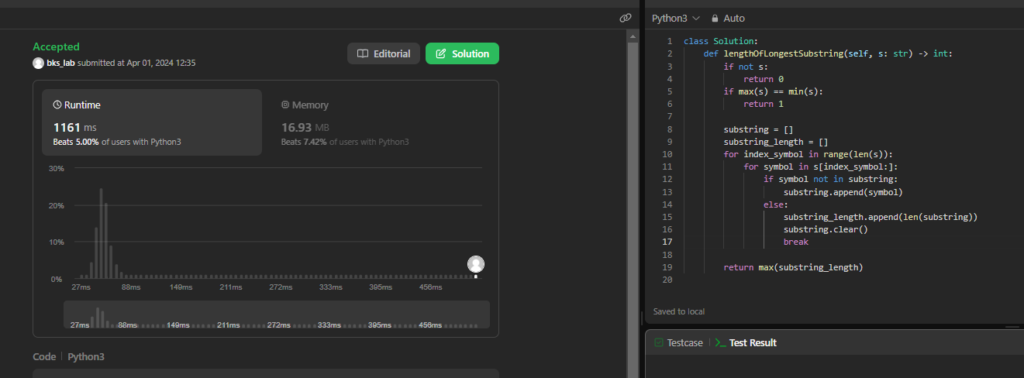
Результаты тестов на LeetCode
- Runtime – 1161 ms — обгоняет 5,00% пользователей Python
- Memory – 16,93 mb — обгоняет 7,42 % пользователей Python
В качестве заключения
Как всегда, я открыт к предложениям о сотрудничестве, конструктивной критике и всему новому и интересному.
Я доступен для связи в Telegram @Kirill_Barabanshchikov или по почте: bks2408@mail.ru
Мой профиль на GitHub: https://github.com/BKSLab