Начинаю год с решения очередной задачи с Leetcode, которая относится к категории easy. Но это точно не значит, что задача окажется легкой для меня.
Как вы уже поняли из заголовка к данной публикации, задача называется Longest Common Prefix. Вот здесь ссылка на саму задачу на LeetCode.

Условия задачи
Вот что от меня требуется, чтобы получить зеленый свет:
«Напишите функцию, которая находит самый длинный общий префикс строки среди массива строк. В том случае, если таковых найдено не будет, необходимо вернуть пустую строку».
Например, функция получает следующий список слов:
word_list = 'flower', 'flow';, 'flight']
На выходе мы должны получить строку, которая будет содержать последовательность букв, общих для каждого из слов в списке. Применительно к списку слов выше мы должны получить:
long_common_prefix = 'fl'
Как показал мой предыдущий опыт, не так и просто фиксировать ход своих рассуждений. Однако, тем интересней научиться этому. Погнали!
Размышления. Начало
Для начала попробуем решить ситуацию с достаточно простыми, как мне кажется, вариантами входных данных. Так, функция на вход может получить список слов, состоящий из одного элемента, то есть одного слова. В этом случае, общим префиксом для такого списка и будет это одно единственное слово.
Для этого мы с помощью функции len() получаем длину списка, а затем делаем следующую проверку:
if length_word_list == 1:
return ''.join(strs)
Oк, все работает, можем идти дальше.
Функция на вход может получить список с одинаковыми словами. А если так, то самым длинным общим префиксом для таких слов будет любое из них, так как слова у нас одинаковые. Вопрос лишь один: как узнать, что слова одинаковые?
На такой вариант я наткнулся в ходе тестирования своего решения на LeetCode, сам я сразу не додумался до такого варианта входных данных. Собственно вот он:
word_list = ['flower', 'flower', 'flower', 'flower']
Для того чтобы определить, являются ли слова одинаковыми, я использовал функции min() и max(), которые применимы к любым итерируемым объектам, к которым в Python относятся и списки строк. Вот такая проверка у меня получилась (strs в функции это наш word_list):
if min(strs) == max(strs):
return strs[0]
Если проверка проходит, то мы возвращаем любое из слов в списке. Я возвращаю первое.
Кстати, пока тестировал этот вариант, пришла мысль, что он применим и к случаю, когда на вход функция получает список, состоящий только из одного слова. Поэтому, код выше с проверкой на длину можно и не использовать.
На этом простые случаи закончились. Возможно, что в ходе тестирования еще что-то возникнет.
Продолжаю рассуждения
Для дальнейшего решения задачи мне понадобятся дополнительные переменные. Так, я добавляю в код переменную temp_long_common_prefix и присваиваю ей пустую строку. Далее эта переменная будет хранить строку, которая получится из букв слов, входящих в список. С начала в строку попадут все первые буквы, потом вторые и так далее.
При переборе любого итерируемого объекта по индексу главное не выйти за его границы. Для того чтобы этого не получилось, я определяю самое короткое слово в списке. Дело в том, что общий префикс в любом случае не будет длиннее самого короткого слова.
Вот так я нахожу длину самого короткого слова в списке:
min_length_word = min(len(x) for x in strs)
А вот и код, который решает описанную выше задачу:
for symbol_index in range(min_length_word):
for element_index in range(length_word_list):
temp_long_common_prefix += strs[element_index][symbol_index]
Посмотрим, как работает этот код. На вход мы даем следующий список:
word_list = ['flower', 'flow', 'flight']
По результатам работы переменная temp_long_common_prefix будет содержать следующую строку:
'ffflllooiwwg'
Получив такую строку, как мне кажется, можно уже посчитать количество вхождений определенных символов. То есть, имея длину списка слов, равную 3, мы должны последовательно определить, являются ли одинаковыми первые три буквы нашей строки, вторые три буквы и так далее. Как только на этот вопрос мы получим отрицательный ответ, поиск прекращается, так как нас интересует только неразрывная последовательность.
Еще раз хочу для себя проговорить механизм дальнейшей работы. Я должен взять любое из слов в списке. Например, это может быть первое слово. По идее, мы можем даже взять самое короткое слово, но это будет дополнительная операция, которая, на первый взгляд, не имеет принципиального значения для решения поставленной задачи.
first_word = 'flower'
Еще для работы мне нужно будет брать срез строки, равный длине списка слов. Именно в этом срезе мы и будем считать количество вхождений и сравнивать его с длиной входного списка.
Кроме того, нам понадобится пустая строка, в которую мы и будем складывать конечный результат.
Работа со срезами
Для каждого среза нам нужно указать первый и последний индексы элемента. При этом, элемент с последним указанным индексом в срез не включается. Длина среза будет равна длине входного списка слов.
Стартовый индекс я задам равным 0, а затем буду его увеличивать на длину списка слов, чтобы смещать срез.
Еще мне понадобиться индекс для выбранного слова, чтобы на каждой итерации последовательно брать по одной букве, количество вхождений которой в срезе и нужно посчитать.
Итак, для перебора срезов мне нужен обычный цикл for, который на каждой итерации будет давать мне срез. На первой итерации я получаю срез всех первых букв слов в списке, затем вторых и так далее.
На каждой итерации я также получаю сначала первую букву выбранного слова, затем вторую и так далее.
Опять же, на каждой итерации цикла я проверяю, равно ли количество вхождений буквы в срезе. Если да, то добавляю эту букву в конечный результат, если нет, прерываю работу цикла, так как нас интересует только последовательность. Собственно, вот такой цикл у меня получился:
first_word = strs[0]
start_index = 0
index_symbol_word = 0
long_common_prefix = ''
for end_index in range(
length_word_list,
len(temp_long_common_prefix) + 1,
length_word_list
):
if (
temp_long_common_prefix[start_index:end_index].count(
first_word[index_symbol_word]
)
== length_word_list
):
long_common_prefix += first_word[index_symbol_word]
start_index += length_word_list
index_symbol_word += 1
else:
break
Пора тестировать получившийся код на платформе LeetCode, так как с локальными входными данными все работает.
Результаты
Runtime – 31 ms — обгоняет 96.84% пользователей Python
Memory – 17:35 mb — обгоняет 14.52% пользователей Python
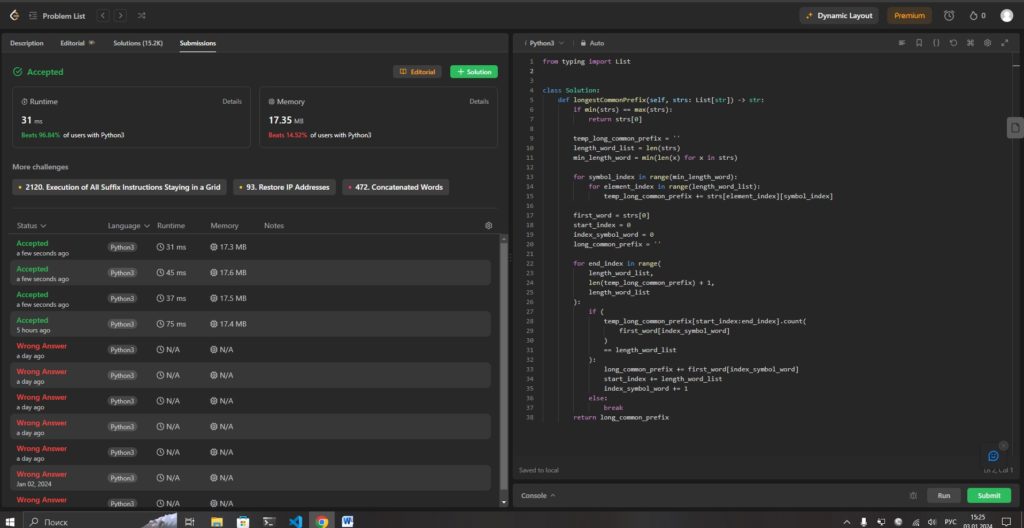
Да, решение мое работает, и LeetCode дает зеленый цвет. Но решение требует много памяти. Да и со скоростью цифры разные. Но оно мое, мое собственное!
Полный код решения:
from typing import List
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
if min(strs) == max(strs):
return strs[0]
temp_long_common_prefix = ''
length_word_list = len(strs)
min_length_word = min(len(x) for x in strs)
for symbol_index in range(min_length_word):
for element_index in range(length_word_list):
temp_long_common_prefix += strs[element_index][symbol_index]
first_word = strs[0]
start_index = 0
index_symbol_word = 0
long_common_prefix = ''
for end_index in range(
length_word_list,
len(temp_long_common_prefix) + 1,
length_word_list
):
if (
temp_long_common_prefix[start_index:end_index].count(
first_word[index_symbol_word]
)
== length_word_list
):
long_common_prefix += first_word[index_symbol_word]
start_index += length_word_list
index_symbol_word += 1
else:
break
return long_common_prefix